Data Health
Access Athinia Catalyst at catalyst.athinia.io.
The Data Health component provides a comprehensive analysis of data quality issues within your dataset. This powerful tool automatically detects and reports various data quality problems, helping you identify potential issues before they impact your analysis.
Key Features
Automated Data Quality Checks
The Data Health component performs several automated checks across your dataset:
- Null Values Detection: Identifies columns with missing values and calculates their percentage
- Non-Unique IDs: Detects ID columns that should be unique but contain duplicate values
- Single Unique Value: Finds columns that contain only one unique value across all rows
- Few Unique Values: Identifies columns with very limited unique values (less than 10)
- High Cardinality: Detects categorical columns with excessive unique values that may impact analysis
- Excessive Cardinality: Flags columns with extremely high cardinality that could cause performance issues
Issue Severity Levels
Each detected issue is classified into one of three severity levels:
- Critical: Issues that severely impact analysis quality and should be addressed immediately
- Warning: Issues that may affect analysis results and should be investigated
- Info: Issues that are informational but may not require immediate action
Filtering and Search
Use the comprehensive filtering system to focus on specific issues:
- Severity Filtering: Click on severity tags (Critical, Warning, Info) to filter issues by level
- Double-click Filter: Double-click a severity tag to show only that level
- Search: Use the search box to find specific issues by column name, issue type, or details
Detailed Issue Information
For each detected issue, the component provides:
- Issue Type: The category of data quality problem
- Column: The affected column name
- Details: Specific information about the issue
- Percentage: The percentage of data affected by the issue
- Issue Level: The severity classification
- Action: Recommended action to address the issue
Using the Component
Generating a Report
The Data Health component automatically generates a report when you have:
- Defined at least one column from any of the following groups: Features (numerical or categorical), Targets, or ID
- Properly configured column groups in your dataset
If no columns are defined in these groups, you'll see a helpful message with a "Define Columns" button that takes you to the edit page to configure your column assignments.
Understanding the Results
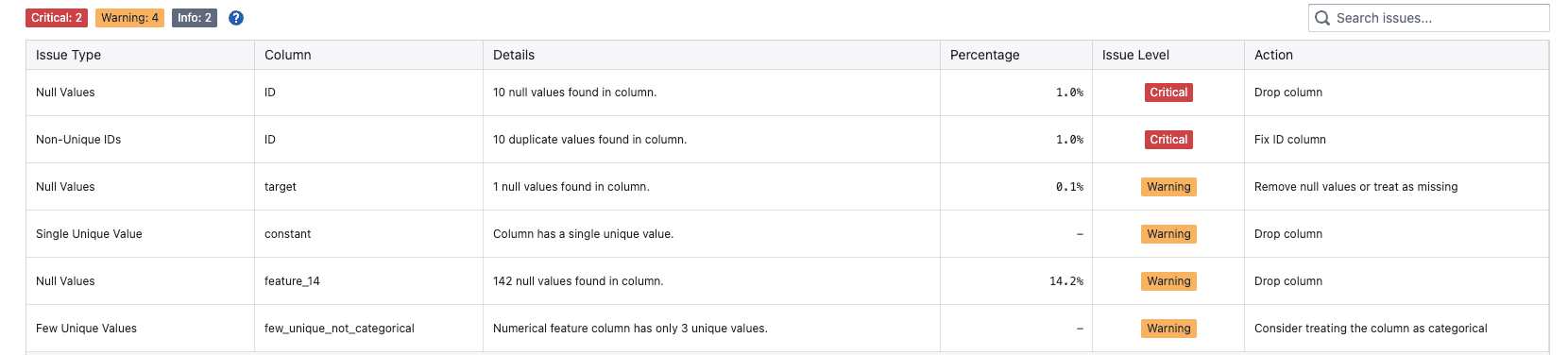
Issue Summary
At the top of the report, you'll see a summary showing:
- Total number of critical issues
- Total number of warnings
- Total number of informational issues
Issue Details Table
The main table displays all detected issues with the following columns:
-
Issue Type: Categories include:
- Data Access: Problems accessing or reading data
- Null Values: Missing values in columns
- Non-Unique IDs: Duplicate values in ID columns
- Single Unique Value: Columns with only one unique value
- Few Unique Values: Columns with very limited diversity
- High Cardinality: Categorical columns with many unique values
- Excessive Cardinality: Columns with extremely high cardinality
-
Column: The name of the affected column
-
Details: Specific information about what was detected
-
Percentage: The percentage of rows affected by the issue
-
Issue Level: Critical, Warning, or Info
-
Action: Recommended steps to address the issue
Recommended Actions
Based on the detected issues, the component suggests various actions:
- Drop Column: Remove columns that provide little analytical value
- Handle Missing Values: Address null values through imputation or removal
- Fix ID Column: Ensure ID columns contain unique identifiers
- Verify Data Type: Check if columns have appropriate data types
- Treat as Categorical: Consider converting high-cardinality columns to categorical
- Reduce Cardinality: Simplify columns with too many unique values
- Monitor Cardinality: Keep an eye on columns with moderate cardinality issues
Data Quality Thresholds
The component uses intelligent thresholds to classify issues:
Missing Values
- Large datasets (≥10,000 rows): Issues flagged when greater than 5% of values are missing
- Smaller datasets (less than 10,000 rows): Issues flagged when greater than 10% of values are missing
Cardinality Issues
- Critical: When unique values represent greater than 20% of total rows
- Warning: When unique values represent greater than 5% of total rows
- Few Unique Values: When a column has fewer than 10 unique values
Tips for Effective Use
-
Start with Critical Issues: Address critical issues first as they have the most significant impact on analysis quality.
-
Review ID Columns: Ensure ID columns are truly unique and consider dropping them if they don't add analytical value.
-
Handle Missing Values Strategically: Consider the context of your analysis when deciding whether to impute, remove, or keep missing values.
-
Evaluate Single-Value Columns: Columns with only one unique value typically don't provide analytical insights and can be safely removed.
-
Consider Domain Knowledge: Use your understanding of the data domain to determine if high cardinality is expected or problematic.
-
Regular Monitoring: Run data health checks regularly, especially when working with new datasets or after data transformations.
Frequently Asked Questions
Why don't I see any issues in my report?
If no issues are detected, it means your dataset passes all automated quality checks. This is displayed with a positive message indicating "No issues found", confirming that your data appears to be in good health.
What should I do about high cardinality warnings?
High cardinality warnings suggest that a column has many unique values relative to the dataset size. Consider whether this column should be treated as categorical, if values can be grouped, or if the column is necessary for your analysis.
How are null value thresholds determined?
The component uses adaptive thresholds: 5% for large datasets (≥10,000 rows) and 10% for smaller datasets. This accounts for the different impacts of missing values in datasets of varying sizes.
Can I customize the thresholds?
The thresholds are currently built into the component and optimized for most use cases. They're based on common data science best practices and research.
What does "Few Unique Values" mean?
This indicates a column has fewer than 10 unique values. While not necessarily problematic, it suggests the column might be categorical in nature or have limited variability.
Why is my ID column flagged as non-unique?
ID columns should contain unique identifiers for each row. If duplicates are found, it may indicate data collection issues, incorrect joins, or the need for a composite key.
How often should I run data health checks?
It's recommended to run data health checks:
- When first loading a new dataset
- After significant data transformations
- Periodically during long-running analyses
- Before sharing results with stakeholders
The Data Health component is designed to be your first line of defense against data quality issues, helping ensure your analyses are built on a solid foundation of clean, reliable data.